



GRAPE:通过偏好对齐提升机器人策略泛化能力
aixiv专栏持续报道全球顶尖ai研究成果。本文介绍一篇来自北卡罗来纳大学教堂山分校、华盛顿大学及芝加哥大学的研究,该研究提出了一种名为grape的新算法,显著提升了视觉-语言-动作(vla)模型的泛化能力。

论文第一作者为北卡罗来纳大学教堂山分校的张子健,指导老师为助理教授Huaxiu Yao。共同第一作者为华盛顿大学的Kaiyuan Zheng。其他作者来自北卡教堂山、华盛顿大学和芝加哥大学。
论文信息:
- 标题: GRAPE: Generalizing Robot Policy via Preference Alignment
- 链接: https://www.php.cn/link/96fb9b48825b741083d35b0137af1be0
- 项目地址: https://www.php.cn/link/009d69d2d1b986815e7b825382d73af5
- 代码地址: https://www.php.cn/link/af12e5e50bc88cf41244cf4ced8988c7
研究挑战与GRAPE的解决方案
现有的VLA模型在机器人任务中的泛化能力有限,主要原因在于它们依赖于成功的执行轨迹进行行为克隆,难以应对新任务和环境变化。 GRAPE算法通过偏好对齐来解决这个问题,其核心思想是将VLA模型与预设目标对齐,从而提升其泛化能力。
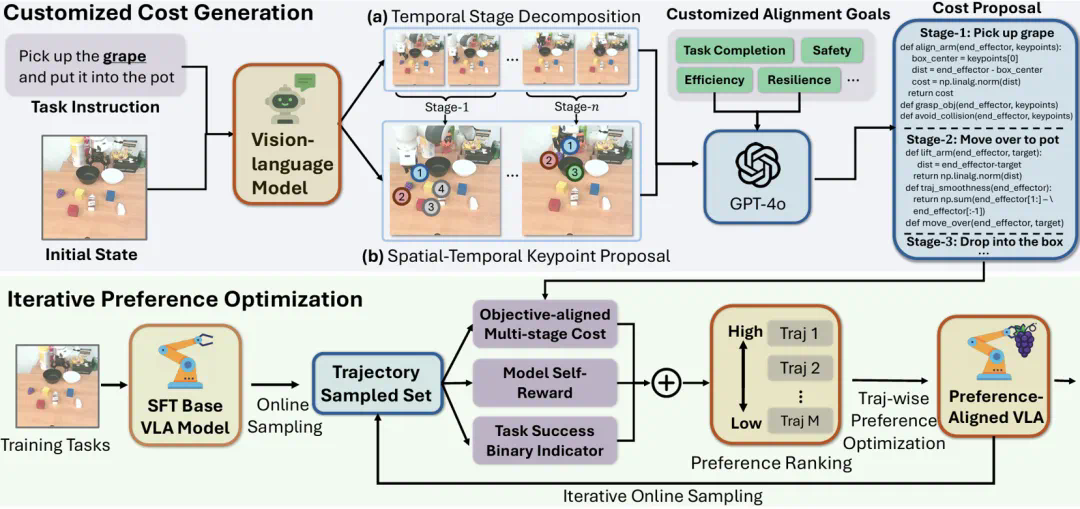
GRAPE具有三大优势:
- 轨迹级强化学习对齐: GRAPE在轨迹层面使用强化学习目标对VLA模型进行优化,使其能够全局地进行决策,而非简单的行为模仿。
- 隐式奖励建模: GRAPE能够隐式地对成功和失败尝试进行奖励建模,从而增强其对多样化任务目标的适应能力。
- 可扩展的偏好合成: GRAPE采用可扩展的算法合成偏好,能够将VLA模型与任意目标(如效率、安全性、任务完成度)对齐。
算法核心模块
GRAPE由三个核心模块构成:
-
轨迹级偏好优化 (Trajectory-wise Preference Optimization, TPO): 通过改进的DPO损失函数(TPO_Loss),根据优劣轨迹样本进行训练,实现轨迹级别的偏好对齐。

-
定制化偏好合成 (Customized Preference Synthesis): 针对复杂任务缺乏明确奖励模型的问题,GRAPE通过大型视觉-语言模型分解任务阶段,并自动引导偏好建模过程,实现对不同目标的定制化对齐。
-
迭代式在线对齐 (Iterative Online Alignment): 通过迭代的在线样本采集、偏好排序和轨迹级偏好优化,逐步提升VLA策略的泛化能力和目标对齐程度。

实验结果与结论
GRAPE在真实机器人和仿真环境下均进行了测试,结果表明其在各种分布外泛化任务(包括视觉、物体、动作、语义和空间位置变化)上显著优于现有最先进的OpenVLA-SFT模型。 此外,GRAPE还能有效地将机器人策略与安全性、效率等目标对齐,例如降低碰撞率或缩短执行时间。
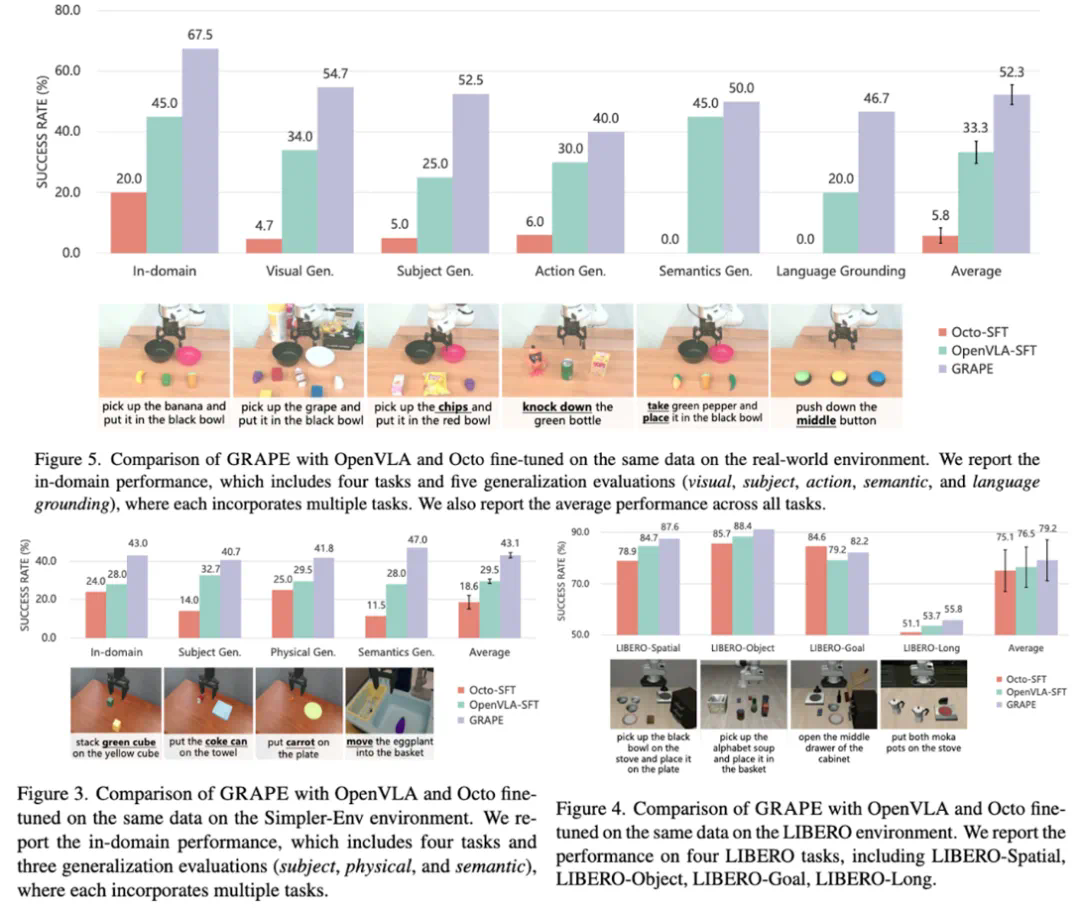
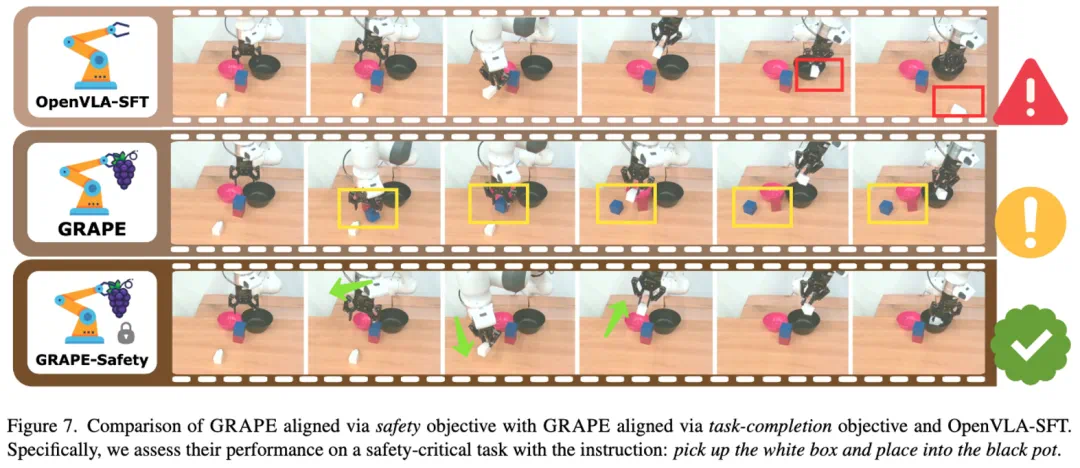
GRAPE为提升VLA模型的泛化能力提供了一种有效的方法,其即插即用的特性使其在各种机器人任务中具有广泛的应用前景。
感谢您的来访,获取更多精彩文章请收藏本站。









暂无评论内容