


利用cpu和gpu协同计算,显著提升大语言模型推理效率!来自cmu、华盛顿大学和meta ai的研究人员提出了一种名为magicpig的新方法,它巧妙地利用cpu上的局部敏感哈希(lsh)技术,有效缓解了gpu内存容量限制,从而大幅提升大语言模型(llm)的推理速度和准确性。
与仅依赖GPU的注意力机制相比,MagicPIG在解码吞吐量方面实现了1.76到4.99倍的提升,并在多个下游任务中取得了优于现有技术(例如Quest)的准确率。
这项研究的主要贡献在于:
-
突破性精度提升: 不同于其他稀疏注意力机制,MagicPIG基于采样和估计而非搜索,从而在保证推理质量的前提下,显著提高效率。
-
高效异构计算: 将解码阶段的注意力计算和哈希表操作卸载到CPU,充分利用异构计算架构,提高吞吐量并降低模型部署成本。
GPU内存瓶颈:KV缓存的挑战
在LLM推理中,KV缓存是主要的性能瓶颈。 KV缓存存储中间注意力键值对,避免重复计算。然而,其内存占用随着批量大小和序列长度线性增长,严重限制了GPU的批量处理能力,导致GPU利用率低下。例如,在NVIDIA A100-40GB GPU上处理Llama-3.1-8B模型(上下文长度128k)时,只能处理单个请求,且近一半的解码时间都耗费在KV缓存访问上。多样性生成和长链式推理等技术进一步加剧了这一问题。
TopK注意力机制的局限性
注意力机制本身具有稀疏性,因此动态稀疏注意力和TopK近似方法被广泛研究。但这些方法通常会造成精度下降。现有技术如Quest、H2O和Loki主要通过选择注意力得分最高的键值对来提高效率,但这种基于TopK的近似方法存在偏差,缺乏理论保障,尤其在高精度要求的任务(如聚合任务、常用词提取、高频词提取和逻辑推理)中表现不佳。
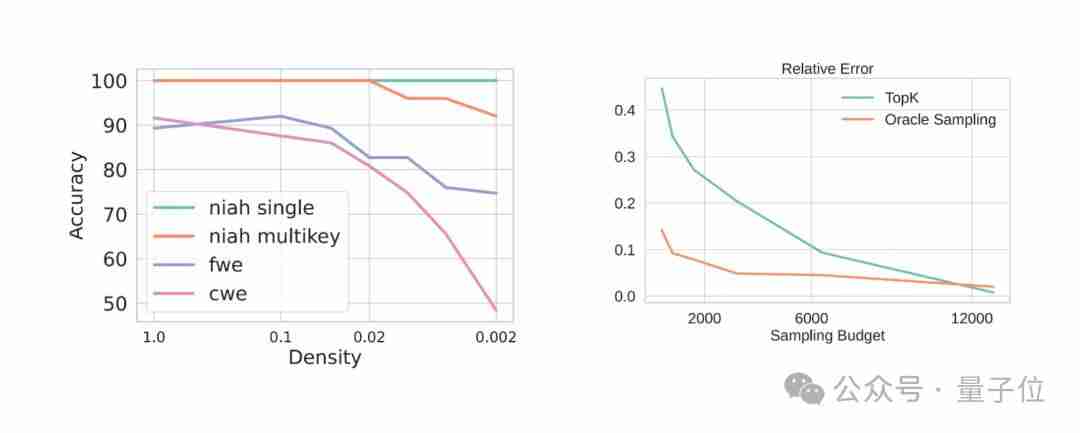
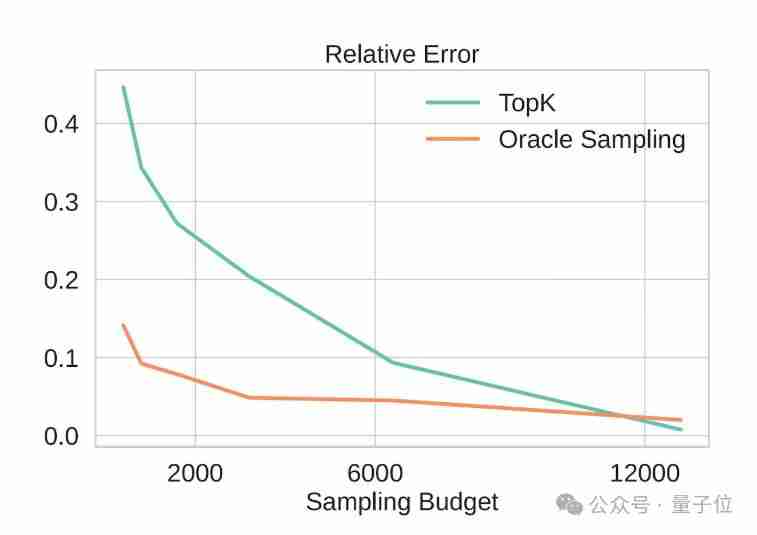
下图显示了TopK注意力机制的估计误差和性能下降:
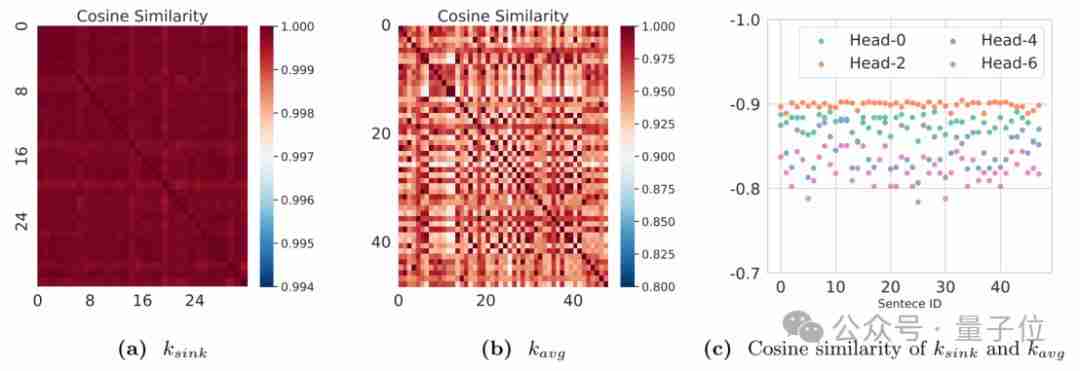
研究人员通过观察发现,TopK方法的失效与以下现象有关:
- 首个输入token的隐藏状态几乎不随输入变化。
- 键状态的中心方向在不同输入句子中保持稳定。
- 键状态的中心与汇聚点token的键状态几乎相反。
下图展示了这些观察结果:
MagicPIG:基于采样的注意力估计
为了解决TopK方法的局限性,MagicPIG提出了一种基于采样的注意力估计方法。 该方法将问题视为偏差校正问题,利用局部敏感哈希(LSH)技术生成采样概率,并通过重要性采样来估计注意力输出。 与TopK方法相比,这种基于采样的方法显著降低了估计误差。
下图对比了基于采样的方法和TopK方法的估计误差:
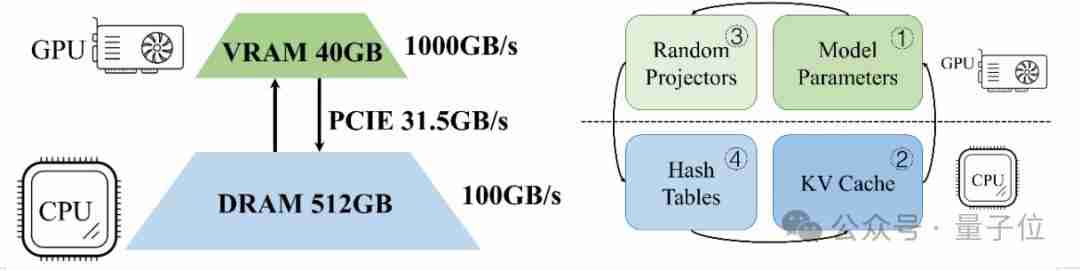
系统设计:CPU-GPU协同工作
MagicPIG将注意力计算和哈希表操作卸载到CPU,充分利用CPU的内存优势。 研究人员发现,通过采样技术降低内存访问量,可以有效弥补CPU内存带宽低于GPU的不足。 系统将LLM解码分为四个部分:参数计算(GPU)、注意力计算(CPU)、随机投影(GPU)和检索(CPU)。
下图展示了MagicPIG的系统架构:
实验结果
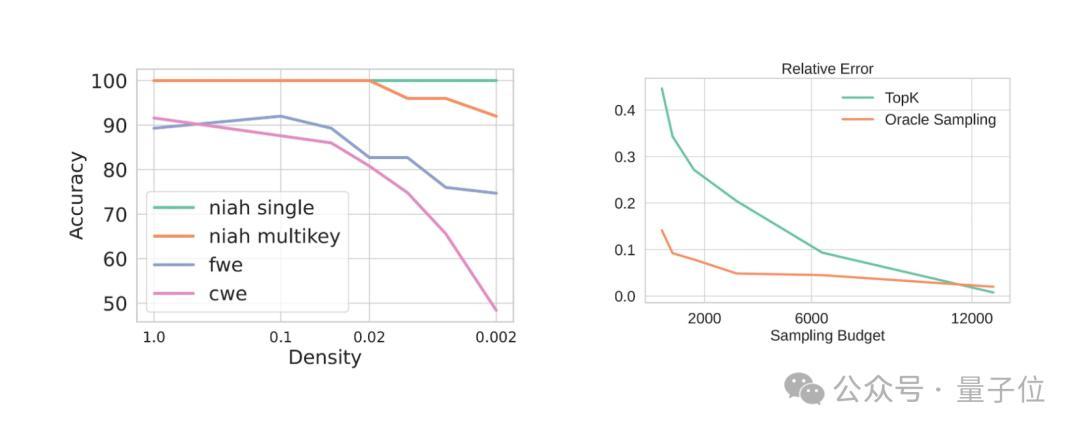
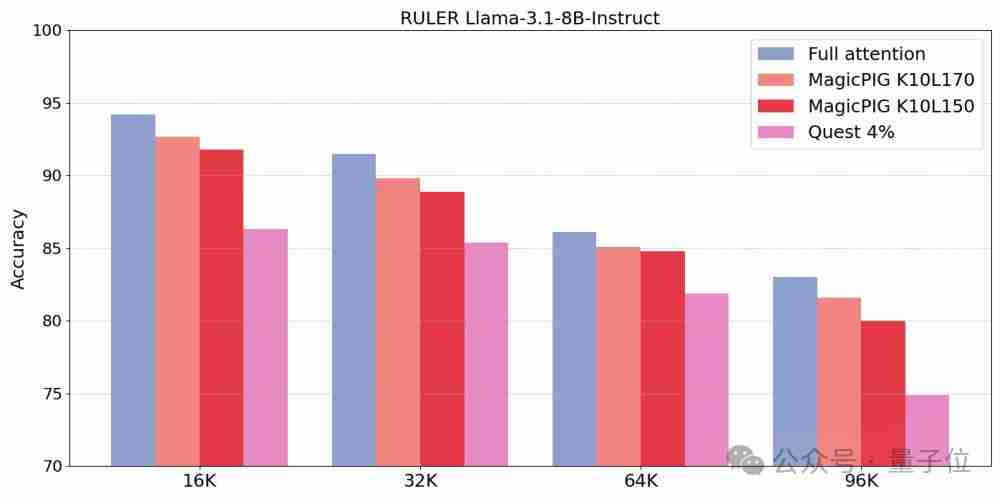
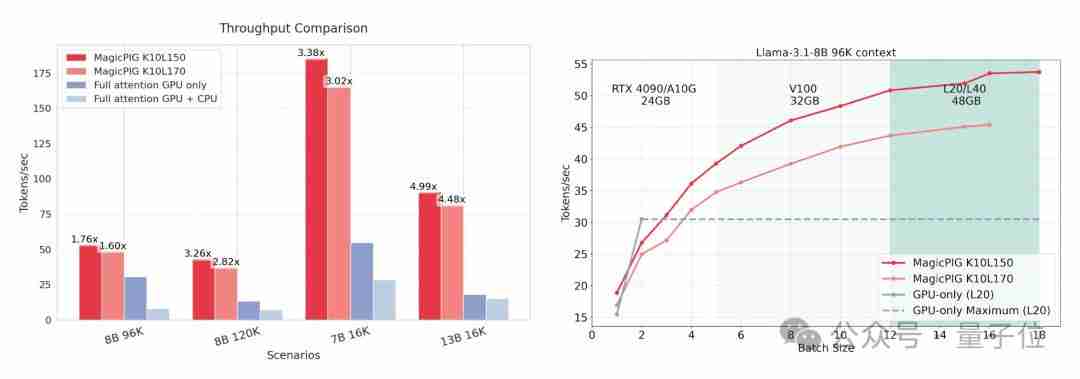
实验结果表明,MagicPIG在长文本RULER任务中取得了比Quest更高的准确率,并且在推理速度和吞吐量方面有显著提升。
下图展示了MagicPIG在长文本RULER任务中的准确率:
下图展示了MagicPIG的吞吐量提升:
总结:MagicPIG 通过巧妙地结合采样技术和异构计算,为高效的LLM推理提供了一种新的思路,有望降低LLM的部署成本并推动其更广泛的应用。
感谢您的来访,获取更多精彩文章请收藏本站。









暂无评论内容